11 min to read
Achitecting on AWS Practice
Migrating from on-premise data center to Cloud Service
Abstract
The traditional e-commerce company, Dayone Corp, plans to migrate from its on-premise data center to AWS while satisfying the following 9 requirements: autoscaling, disaster recovery, scalable database, low latency, self-healing infrastructure, security, archiving, IaC, and cost effectiveness. The proposal delineates the architecture diagram and explains how each element is related to the customer’s requirements.
Overview
Features
Region, VPC, Availability Zone, Subnet
Amazon Web Service(AWS) provides diverse cloud computing services worldwide. To ensure high availability and fault tolerance, AWS hosts its resources in accordance with a multi-tier hierarchy. AWS consists of multiple regions, which are geographically apart. Each region consists of several Availability Zones(AZ), which is a group of multiple adjacent data centers. Amazon Virtual Private Cloud(VPC) enables logical isolation of its resources from the resources from other VPCs. Subnet, a range of IP addresses in a VPC, also isolates resources in each subnet from those in other subnets.
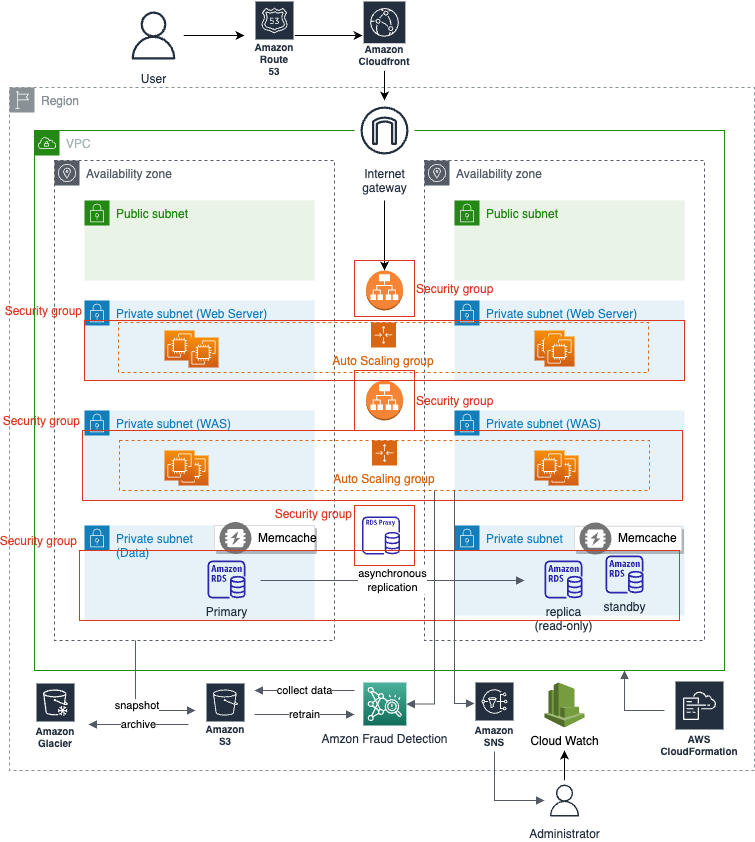
The proposed architecture provides a highly available 3-tier web application service with a single VPC in a single region. The VPC consists of two AZs which means the Dayone Corp’s application is hosted in different data centers. Any failure in one AZ is backed up by the other AZ. For example, each AZ receives 50% of total requests when everything goes right but an active AZ receives 100% of total requests when the other AZ goes wrong by flood, power shortage, etc. Consistent with the modularity of 3i-tier web applications, each AZ is splitted into 3 private subnets, each of which matches web server layer, web application server layer, and data layer. The isolated subnets facilitate managing already-modularized servers, making each layer independent to other layers.
Auto Scaling Group
The proposed architecture adopts Auto Scaling group to meet the demand which is unpredictable at the moment. Auto Scaling group monitors and manages a collection of EC2 instances by predefined configurations. Auto Scaling group maintains the number of healthy instances through periodical health checks and terminating/launching instances. The management by the group makes EC2 instances self-healing. Web server EC2 instances and web application server EC2 instances are designated to distinct Auto Scaling groups. Thus, different configurations, such as the number of minimum instances, desired instances, maximum instances, are applied to different layers independently. Also, each Auto Scaling group is connected to a load balancer respectively. The connection helps load balancers to distribute incoming requests even though the addresses to instances may change during the auto scaling process. A single Auto Scaling group is able to manage resources in different AZ since AZs are interconnected with high-speed links.
Choosing an appropriate scaling strategy saves costs by preventing Dayone Corp from buying resources excessively. Among several scaling strategies, Dayone Corp had better adopt dynamic scaling in the short term and scheduled scaling/predictive scaling in the long term. Dynamic scaling is suitable to meet the fluctuating demand on the spot. It adjusts the number of instances by policy. For instance, Auto Scaling group launches a new instance when CPU utilization rate reaches a certain threshold. After piling up a certain amount of user activities data with dynamic scaling, Dayone Corp is able to predict the user’s demands. CloudWatch monitors the users’ activities and logs statistics related to the demand. If the user activities are simple, Dayone Corp had better switch to scheduled scaling, which resizes the resources by time and date. For example, Double the number of web application servers on Friday between 6pm and 10pm. On the contrary, if the data are too complex to cover its tendency by simple scheduling, Dayone Corp might as well utilize predictive scaling which takes advantage of machine learning models.
Private Subnet, Security Group
The architecture enhances security by isolating resources in private subnets and securely managing interaction between resources by utilizing security groups. The primary step to protect our infrastructure is to block unauthorized traffic from the Internet. The architecture protects Dayone Corp’s resources by subnetting its VPC and placing all resources in private subnets. Resources in private subnets have only private IP addresses making themselves invisible to hackers in the Internet but visible to resources in the same VPC. Traffic should pass the Internet Gateway and the Load Balancer to reach any resources of the 3-tier application. In addition, the subnet has a network ACL(Access Control List) which manages both inbound and outbound traffic at the subnet level.
On top of blocking traffic from the Internet, the architecture secures each tier by security groups, following the principles of least privilege. Security groups manage the interaction between resources inside the VPC. Web servers’ security group only accepts traffic from the first load balancer’s security group and sends traffic to the second load balancer’s security group. Likewise, WAS tier’s security group allows inbound only from the second load balancer’s security group and outbound to RDS proxy’s security group. However, the traffic from the Web server layer to the Data layer is not allowed. Thus, security issues in a certain security group are confined to the resources in security groups connected to the breached security group.
RDS, RSD proxy
Assuming Dayone Corp makes use of RDBMS, the architecture proposes AWS RDS and RDS Proxy to satisfy configurability and scalability. It is easy to configure and provision RDS: a click or a simple command is all you need. When it comes to vertical scaling, upgrading capability of the database, AWS RDS provides a wide range of options. If the workload is unpredictable, Amazon RDS storage autoscaling manages the database capacity.
In addition, the architecture proposes horizontal scaling as well. Apart from the primary database, additional nodes handle read-only requests to the data layer. The primary database handles all write operations and the updated transactions are asynchronous replicated to other replicas. When the primary database goes down, one of the replicated nodes becomes a primary node, maintaining the availability of the data layer. RDS also terminates the malfunctioning node and launches a new node, making itself self-healing.
The architecture suggests Amazon RDS proxy to distribute read requests from WAS to multiple nodes across multiple AZs without failure. Since the proxy is connected to all nodes, the web application servers point to the proxy endpoint instead of instances’ endpoints. Therefore, even though each instance’s endpoint changes occasionally due to undesired incidents such as termination and relaunch, the requests from web application servers work well without additional measures.
To boost performance, the architecture places Memcache in the data-tier layer to handle frequently requested queries. To backup data, RDS periodically exports the snapshot of the database to a S3 bucket.
S3, Glacier
The architecture shows how database snapshots, Amazon Fraud Detection data, and other static data are stored in S3. S3 is a highly available, easy-to-connect, and securely protected object storage. S3 is partitioned by buckets and each bucket independently follows the policy of its own. S3 also provides data versioning features. S3 keeps track of the history of its object and reverts the object when the older version is requested. To utilize S3 cost-effectively, it is important to monitor storage usage through CloudWatch. Dayone Corp might as well set CloudWatch to send an alarm when S3 reaches a certain amount of cost.
AWS provides a more economical option when archiving data: Glacier. S3 is designed for a fast retrieval. However, Glacier focuses on archiving less-frequently retrieved objects with lower price. Glacier costs approximately $0.01 for archiving 1GB per month; for more information about S3 options and pricing, please consult with aws website. Thanks to the connectivity between AWS resources, archiving Amazon S3 data to Glacier can be automated by setting the object’s lifecycle policy. For example, since Dayone Corp wants to archive objects inactive longer than 6 months, S3 lifecycle policy will be configured to automatically transition inactive S3 objects to Glacier after 180 days. Furthermore, we can use expiration settings to delete objects permanently in Glacier to reduce the archiving cost.
CloudFormation
AWS CloudFormation is a free Infrastructure as Code(IaC) service which enables blueprinting the whole AWS infrastructure and replicating the same infrastructure at other regions. Cloudformation supports json and yaml templates and Dayone Corp is able to provision resources like load balancers, EC2, RDS as a code, configuring options as parameters. Using CloudFormation, Dayone Corp can replicate the production environment from the dev environment template, eliminating repetitive tasks and reducing managing cost. Under the disastrous incidents, the IaC service allows Dayone Corp to reconstruct the infrastructure in the other region easily. Please consult with CloudFormation best practices so as to make the most out of the IaC service.
CloudFront, Route53
The proposed architecture makes use of AWS Cloudfront and Route53 to provide Dayone Corp service with low latency even for the requests from disant locations. AWS Cloudfront is a Content Delivery Network service that speeds up the response time, serving static and dynamic content at the data centers near the user called edge location. For example, when Dayone Corp’s user requests html and image files from the website, Cloudfront delivers those contents from the near edge location on behalf of resources at the distant region. If the requested contents do not exist in the edge location, Cloudfront retrieves those contents from the resources in the specified region. Route53 is a Domain Name System(DNS) service with high availability. Route53 maps human-friendly domain names to Cloudfront’s auto-generated domain names.
Disaster Recovery
The architecture adopts a multi-AZs approach and active/active strategy to pre-empt failures under disaster events. Each Availability Zone is geographically apart from other AZs. When disastrous events by natural disasters, technical failures and human actions make resources in one AZ malfunctioning, the other resources in the other AZ handles all the traffic until the malfunctioning resources get recovered. However, to prepare for disasters of intercontinental impact, it is recommended to choose a multi-Regions approach: establishing a backup plan in other regions. Active/active strategy maintains multiple sites to guarantee zero downtime.
We need to focus on the tradeoff between RTO(Recovery Time Objective)/RPO(Recovery Point Objective) and cost whening choosing disaster recovery strategies:
The cost-effective approach is to choose an economical strategy as long as it meets business logic. More details are described in an AWS Architecture Blog post.
CloudWatch
It is important to monitor the activities of resources in order to keep the service highly available and cost-effective. AWS CloudWatch provides system event streams nearly in real-time. With CloudWatch, Dayone Corp administrators can monitor any change in resources and react immediately when undesired incidents occur. For example, after deploying a new version of an application, developers can easily monitor the service through CloudWatch. If its log dashboard displays critical error messages, they can rollback to the latest version. CloudWatch also helps to reduce cost. For instance, CloudWatch shows user activities, cpu utilization, etc, providing the administrators with the data to determine auto scaling group configuration. If the cpu utilization rate is low enough, Dayone Corp can reduce operation cost by decreasing the number of EC2 instances.
Amazon Fraud Detector
Amazon Fraud Detector(AFD) provides easy-to-apply anomaly detection models through machine learning. Applying machine learning models into the real world services entails complex processes and considerable amounts of effort: building machine learning team, collecting/preprocessing/versioning data, deploying the trained model, updating model through continual learning. Amazon Fraud Detector compresses those processes into a few simple clicks.
The architecture train/deploy/update machine learning model utilizing AFD. First, train data should be stored in S3 bucket. AFD imports data from the S3 bucket and selects/trains a machine learning model based on the features of the imported data. After training, Amazon Fraud Detector deploys the customized model and creates an endpoint to process requests in real-time. Web application servers may send requests to the endpoint to detect abnormal activities. If positive, they trigger Amazon SNS to send notification to the admin. The architecture also builds a human-in-the-loop machine learning pipeline. Inbound requests stored in S3 will be used as training data to improve the model’s accuracy after data processing/annotation.
Amazon Fraud Detector provides a handful of ways to improve model performance one more step. With AFD, Dayone Corp can add rules to pinpoint abnormal activities. For example, we can configure the specific threshold of being abnormal. We can also filter fraudulent users by setting conditions using several features such as email address and/or phone number. In addition to adding rules, AFD allows you to deploy the customized model using Sagemaker. If Dayone Corp fortunately possesses a well-trained machine learning model, all we need to do is switch the model while taking advantage of the inference pipeline provided by Amazon Fraud Detector.

Comments